Pero la F1 no es solo deporte, sino que esconde una industria multimillonaria basada en la tecnología más vanguardista y que va desde la innovación en materiales, el diseño aerodinámico, las sofisticadas unidades de potencia híbridas hasta, incluso, los materiales con los que se confeccionan las prendas de los pilotos.
El entorno de la Formula 1 hace un uso intensivo de las tecnologías más avanzadas en cuanto a comunicaciones y Big Data, y es el análisis de las ingentes cantidades de datos que se generan cada minuto de un fin de semana de Gran Premio lo que hace especial a la competición.
Sin análisis de Big Data en tiempo real, la F1 actual sería muy diferente. Cada segundo se generan centenares de «puntos de datos» en todas las piezas relevantes de los coches, y los ingenieros y analistas de datos, tanto en el circuito como en la fábrica, a miles de kilómetros de distancia, compiten por extraer la máxima información de ellos y traducir dicha información en «armas» para luchar por la victoria.
¿Qué datos se generan en un coche de Formula 1? ¿Cómo se analizan los datos procedentes de los centenares de sensores repartidos por los coches? ¿Cómo la información que se obtiene es vital para conseguir llegar a la meta un segundo antes que los competidores?
300
GB de datos generados
¿Qué datos se generan en un fin de semana de carreras de F1?
El volumen de datos generados por cada coche individual durante un gran Premio de Formula 1 es ingente. Todo empezó con cronómetros y pizarras, para pasar en la década de 1990 a ordenadores básicos, enfocados en interpretar las pocas decenas de datos recogidas durante una prueba, hasta llegar a la recogida masiva y análisis en tiempo real de la actualidad.
La Formula 1 es una industria basada en datos, y siempre lo ha sido. Sin embargo, no es hasta esta década pasada cuando las simulaciones han alcanzado un nivel de sofisticación y velocidad tal que pueden influir de manera drástica en el devenir de una prueba.
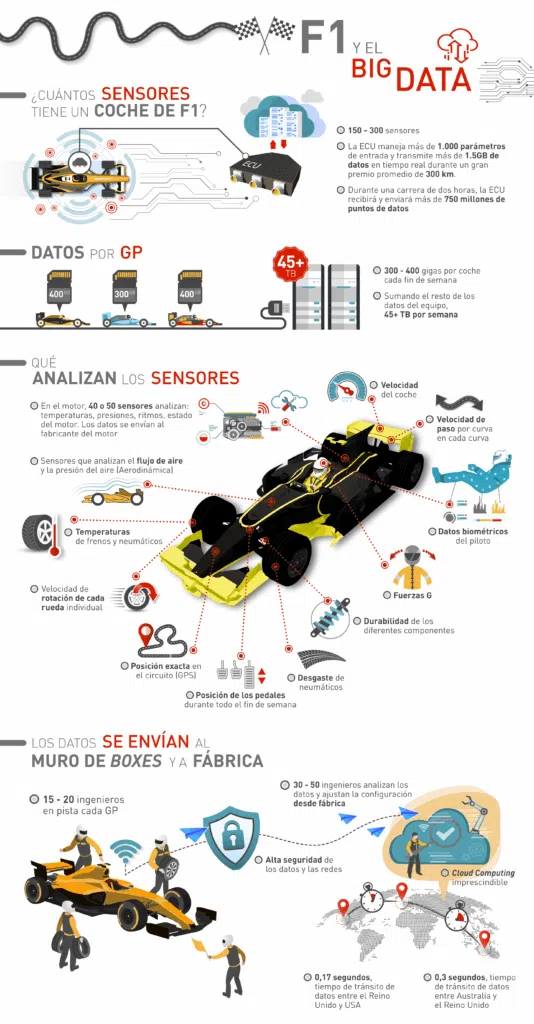
Hoy, cada coche incluye entre 150 y 300 sensores que generan millones de «puntos de datos» cada fin de semana. En números, podemos hablar de unos 300 GB de datos generados cada fin de semana de Gran Premio, por cada coche. Si agregamos a estos datos todos los que se generan en cualquier otro departamento de un equipo, podemos llegar a los 40-50 TB de datos por semana.
Manejar toda esta cantidad de datos es ciertamente exigente, y requiere de la tecnología más avanzada tanto para la propia recogida de datos, como para su almacenamiento seguro o las comunicaciones con el exterior (principalmente, con la fábrica y los departamentos de ingeniería). Además, la potencia de computación necesaria para llevar a cabo análisis de datos en tiempo real es cada vez mayor.
Por eso, las diferentes escuderías se han aliado con empresas especializadas en computación en la nube y data analytics. De esta manera, cada equipo puede confiar en sus partners para delegar cierta parte del análisis de datos y centrarse puramente en competir contra el resto de la parrilla.

Todos esos millones de puntos de datos recopilados por los sensores en el coche son analizados y enviados a los ingenieros. Estos, a partir de los resultados observados, disponen de información para seguir con el desarrollo correcto de los coches en aerodinámica, prestaciones y manejabilidad, además de obtener valiosa información para la puesta a punto de los coches en cada circuito.
Para hacernos una idea de la cantidad de puntos de datos que se generan durante una carrera de F1, pondremos unos cuantos ejemplos. Tan solo en el motor de combustión podemos contar entre 40 y 50 sensores que analizan todos los parámetros críticos, desde temperaturas instantáneas, presiones, velocidad de giro en revoluciones por minuto, el estado del motor y muchos otros.
Esos datos se envían al fabricante del motor para su análisis y para poder saber, por ejemplo, si la durabilidad del motor será suficiente como para terminar la carrera, o qué probabilidad hay de que el motor se rompa y establecer con mayor o menor exactitud cuándo terminará su vida útil.
Repartidos por todo el coche nos podemos encontrar con sensores que analizan el flujo de aire y la presión del aire, vitales para el departamento encargado de la aerodinámica; sensores de temperatura en frenos y neumáticos; sensores que registran la velocidad instantánea del coche, la de paso por curva (en cada curva del circuito), la velocidad de rotación de cada rueda; sensores que miden las fuerzas G experimentadas por el conjunto.
Existen otros sensores capaces de dar la posición del vehículo en cada punto del circuito con precisión de centímetros; otros que informan del desgaste exacto de cada neumático; otros que informan de las posiciones exactas de los pedales del coche, una información que se puede contrastar con la que procede del motor, por ejemplo; incluso existen sensores dedicados exclusivamente a registrar datos biométricos de los pilotos (ritmo cardíaco, respiración, sudoración…) y que sirven para detectar si, por ejemplo, el piloto está en riesgo de deshidratarse.
Análisis de Big Data, crucial para la victoria
El análisis de toda esa enorme cantidad de datos generados por cada coche y piloto durante un fin de semana de carreras es la diferencia entre la victoria y la derrota. A lo largo de estos últimos años, encontramos decenas de ejemplos de cómo el buen análisis de los datos convirtió una carrera aparentemente perdida en un éxito.
Quizás, el más espectacular de todos los ejemplos lo tenemos en el Gran Premio de Brasil, en 2012. Sebastian Vettel, dominador del año junto con Fernando Alonso, necesitaba terminar la carrera entre los tres primeros para proclamarse campeón del mundo por tercera vez consecutiva.
En la primera vuelta, alguien impactó por detrás en su monoplaza y Vettel quedó último. La carrera parecía perdida, pero los ingenieros entraron inmediatamente en juego comprobando, en primer lugar, si el coche podría terminar la carrera o no. Antes de finalizar la primera vuelta del GP, el equipo conocía el alcance de los daños sufridos y supo que había un problema de balance que podría afectar a los neumáticos y al motor.
Pocas vueltas después, el equipo tenía la solución al problema y, para cuando Vettel hizo su primera parada en boxes, en la vuelta 10, los mecánicos sabían qué tocar en el coche para solucionarlo y los ingenieros habían creado una estrategia para conseguir el objetivo: ganar el mundial. Sexto al pasar bajo la bandera a cuadros, Vettel se convirtió en el tricampeón del mundo más joven de la historia, tres puntos por delante de Fernando Alonso, quien se quedó a las puertas de su tercer título mundial.
Más allá de este ejemplo, el análisis de Big Data en los Grandes Premios de Formula 1 es una herramienta imprescindible para el desarrollo de los coches, para el diseño de las estrategias de carrera y para mejorar décima a décima el rendimiento del conjunto coche-piloto.